




Soluciones de Lago en Tiempo Real: Integración de Apache Flink y Apache Paimon
En el entorno actual de datos, las arquitecturas que combinan la flexibilidad de los lagos de datos con las características de rendimiento de los almacenes de datos tradicionales son esenciales. A medida que las empresas adoptan cada vez más el análisis en tiempo real para tomar decisiones comerciales, la combinación de Apache Flink como motor de procesamiento de flujos con Apache Paimon como formato de almacenamiento en lago se ha convertido en una solución atractiva para construir potentes plataformas de lago en tiempo real.
En el reciente evento Apache CommunityOverCode Asia 2025, Xuannan Su, experto técnico de Alibaba Cloud y committer de Apache Flink, compartió profundas ideas sobre la evolución continua de las soluciones de lago en tiempo real de Flink construidas sobre Paimon. Este análisis técnico explora las optimizaciones clave y las mejoras arquitectónicas desarrolladas para abordar los desafíos del mundo real en la implementación de plataformas de análisis de flujos a gran escala.
A medida que aumenta el volumen de datos estructurados y semi-estructurados, los enfoques tradicionales de procesamiento de datos a menudo luchan con el rendimiento, la eficiencia de costos y la complejidad operativa. Las mejoras discutidas representan soluciones prácticas y probadas en producción para las organizaciones que buscan modernizar su infraestructura de datos, proporcionando un camino claro para implementar canalizaciones de datos en tiempo real escalables.
Arquitectura del Lago en Tiempo Real con Flink y Paimon
Antes de profundizar en las optimizaciones técnicas, es fundamental comprender los patrones arquitectónicos típicos formados en torno a la integración de Flink y Paimon. El enfoque de lago en tiempo real representa un cambio fundamental de los modelos tradicionales de almacén de datos orientados a lotes, abrazando un paradigma donde los datos se procesan continuamente a medida que llegan.
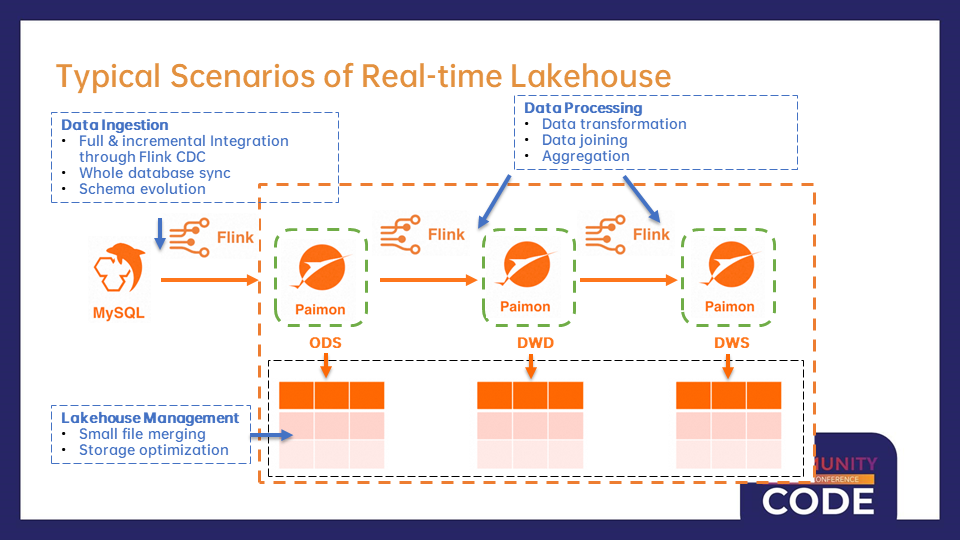
Componentes de Infraestructura Clave de la Arquitectura del Lago en Tiempo Real
Los lagos en tiempo real modernos construidos sobre Flink y Paimon típicamente consisten en capas de procesamiento interconectadas, cada una de las cuales sirve propósitos distintos mientras mantiene un flujo de datos continuo a través del sistema. En la capa fundamental, Flink CDC (Change Data Capture) juega un papel crítico al establecer capacidades unificadas para la sincronización de datos de carga completa e incremental.
Flink CDC ha demostrado ser especialmente valioso para conectar bases de datos operativas y sistemas analíticos. A diferencia de los complejos pipelines de ETL que requieren horarios fijos, Flink CDC permite a las organizaciones capturar cambios en tiempo real desde sistemas de origen como MySQL y transmitirlos directamente a la capa ODS (Operational Data Store) de Paimon. Este enfoque reduce la latencia y simplifica la arquitectura al eliminar áreas intermedias de staging y complejos mecanismos de coordinación.
Capacidades de Procesamiento y Transformación de Datos
Una vez que los datos ingresan al lago a través de capas de ingesta, pasan por una serie de etapas de procesamiento para refinar y enriquecer la información. La capa de Data Warehouse Detail (DWD) representa la primera fase importante de transformación, donde los datos operativos en bruto se limpian, normalizan y enriquecen.
Estas transformaciones a menudo implican uniones complejas de datos para crear «tablas anchas» al combinar información de múltiples sistemas de origen. Por ejemplo, una organización de comercio electrónico podría fusionar perfiles de clientes con el historial de transacciones, catálogos de productos y datos de campañas de marketing para construir una vista integral del comportamiento del cliente. La naturaleza en tiempo real de este procesamiento asegura que estas vistas enriquecidas se mantengan actualizadas a medida que evolucionan los datos de origen, proporcionando información fresca a analistas y aplicaciones sin los retrasos inherentes al procesamiento por lotes.
Gestión y Optimización de Lago
La gestión de datos dentro de un lago presenta desafíos únicos distintos de la gestión tradicional de almacenes de datos. Paimon aborda estos desafíos con un conjunto completo de herramientas de gestión de lagos y técnicas de optimización que operan de manera transparente para mantener el rendimiento y la eficiencia del sistema.
La gestión de archivos pequeños representa uno de los desafíos operativos más críticos en cualquier sistema de almacenamiento basado en lagos. A medida que los datos de flujo llegan continuamente, esto conduce naturalmente a la creación de numerosos archivos pequeños, lo que degrada el rendimiento de lectura y aumenta la sobrecarga de metadatos. La función de fusión automática de Paimon resuelve esto al fusionar inteligentemente archivos pequeños basados en políticas configurables, asegurando que el almacenamiento se mantenga optimizado sin intervención manual.
Optimización Técnica: Claves para el Manejo de Datos Semi-Estructurados
La maduración del ecosistema de Flink y Paimon ha impulsado optimizaciones cada vez más sofisticadas para abordar cuellos de botella en el rendimiento y desafíos operativos en implementaciones de producción. Dos avances particularmente significativos incluyen el manejo mejorado de datos semi-estructurados y operaciones de Lookup Join optimizadas.
Desafíos de Datos Semi-Estructurados
Los entornos de datos modernos se caracterizan por la proliferación de formatos de datos semi-estructurados, siendo JSON el más prevalente. La creciente utilización de aplicaciones web, dispositivos móviles, sensores IoT e integraciones impulsadas por API ha hecho que JSON sea omnipresente en las canalizaciones de datos empresariales. Sin embargo, su uso generalizado introduce desafíos de rendimiento notables cuando se procesan con enfoques tradicionales de procesamiento de flujos.

Solución del Tipo de Datos Variant
La introducción del tipo de datos Variant marca un cambio fundamental en el enfoque de Flink hacia el procesamiento de datos semi-estructurados. En lugar de tratar JSON como texto opaco, Variant proporciona una representación binaria nativa que mantiene la flexibilidad de los datos semi-estructurados mientras entrega un rendimiento más cercano al procesamiento de datos estructurados.

La estrategia de codificación binaria de Variant logra mejoras de rendimiento a través de múltiples mecanismos. La información del esquema se codifica una vez en secciones de metadatos, reduciendo drásticamente la sobrecarga de almacenamiento. Las operaciones de acceso a los campos aprovechan estos metadatos para navegar directamente a campos específicos sin analizar partes irrelevantes de la estructura de datos, mejorando significativamente la selectividad en el rendimiento de las consultas.
Optimización del Lookup Join: Abordando Cuellos de Botella de Escalabilidad
La segunda gran optimización aborda un patrón arquitectónico común en análisis en tiempo real: enriquecer los datos de flujo con información de dimensión almacenada en tablas Paimon. Los Lookup Joins representan una operación crítica en la analítica de flujos, donde los datos de eventos en tiempo real deben ser enriquecidos con información de dimensión relativamente estática.
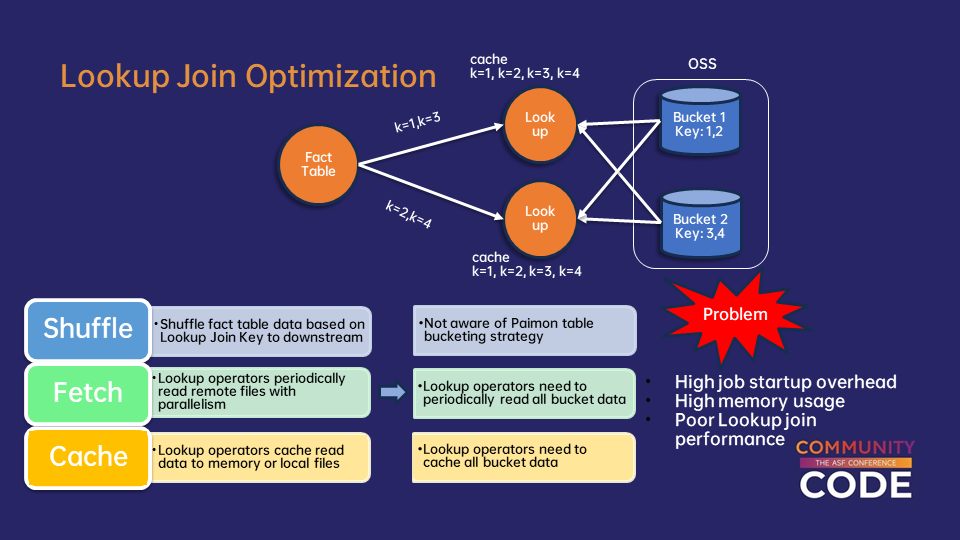
La solución implica extender la arquitectura de Lookup Join de Flink para admitir estrategias de distribución personalizadas. Esta alineación asegura que los registros que se espera que se conecten a cubos específicos de Paimon sean procesados por el mismo operador de Lookup responsable de los datos de dimensión de ese cubo. Con esta alineación, cada operador de Lookup se enfoca exclusivamente en los datos de su cubo asignado, manteniendo solo una copia local de su subconjunto de datos, reduciendo drásticamente el volumen de datos que cada operador debe gestionar.
Características de Optimización Adicionales
Más allá de los avances centrales de los tipos de datos Variant y las optimizaciones de Lookup Join, la integración de Flink y Paimon incluye características críticas adicionales que forman un ecosistema completo de optimización de lago en tiempo real.

Mejoras de Usabilidad de Acciones/Procedimientos de Paimon
Las mejoras en la usabilidad de las Acciones y Procedimientos de Paimon representan una importante actualización de UX. Las operaciones de gestión del lago de datos a menudo requieren configuraciones complejas y un profundo conocimiento técnico, creando una alta barrera para los equipos de desarrollo y operaciones. Las nuevas mejoras de usabilidad simplifican las tareas comunes de gestión del lago, permitiendo a los usuarios realizar estas tareas con declaraciones SQL sencillas.
Soporte de Tablas Materializadas
Las Tablas Materializadas recientemente introducidas en Flink permiten a los usuarios escribir lógica empresarial en Flink SQL mientras deciden automáticamente si lanzar trabajos de transmisión o por lotes en función de los requisitos de frescura especificados. Esto elimina la necesidad de configuración y mantenimiento manual de trabajos.
Perspectivas Futuras: Innovación en Datos Semi-Estructurados
Las futuras mejoras se centrarán en la automatización y la inteligencia. La fragmentación de Variant admitirá la identificación automática de campos, donde los sistemas analizarán patrones de consulta históricos y frecuencias de acceso para determinar campos óptimos de fragmentación sin configuración manual.
La hoja de ruta de Flink incluye extensiones significativas al procesamiento de datos no estructurados, lo que permitirá aplicaciones más amplias como el análisis de contenido, procesamiento multimedia y análisis de documentos, consolidando el papel de Flink como una plataforma de procesamiento de datos unificada.
Estas innovaciones seguirán mejorando la posición de Flink como una solución completa para arquitecturas de datos modernas, empoderando a los desarrolladores para construir sistemas escalables y en tiempo real con una flexibilidad y rendimiento sin precedentes.
Fuente: Alibaba Cloud Blog
Nota: Este contenido original ha sido modificado con IA y revisado por un especialista. Imagen generada por IA.



