Técnicas de Normalización de Texto Mediante Hashing Sensible a la Localidad
El presente documento aborda la técnica de hashing sensible a la localidad (LSH) como una solución eficaz para la limpieza y normalización de registros de texto. Esta técnica es especialmente útil en el contexto del análisis de datos textuales, donde la calidad de los conjuntos de datos es crucial para el éxito de modelos de aprendizaje automático y otras aplicaciones de procesamiento de lenguaje natural.
Introducción al Hashing Sensible a la Localidad
El hashing sensible a la localidad permite agrupar palabras o tokens que son similares entre sí en el espacio de características, facilitando la identificación de variantes léxicas. Este enfoque es particularmente relevante para gestionar datos textuales que contienen errores de ortografía, variaciones morfológicas o puntuación no estándar, que son comunes en datos extraídos de fuentes como redes sociales y registros de búsqueda.
Ventajas del Uso de LSH
Una de las principales ventajas del LSH es su capacidad para manejar múltiples variaciones de palabras en un solo proceso, eliminando la necesidad de heurísticas explícitas. Además, las estructuras de grafo construidas a partir de LSH se ajustan a la distribución del conjunto de datos, lo que permite que no se requieran etiquetas adicionales o aprendizaje supervisado.
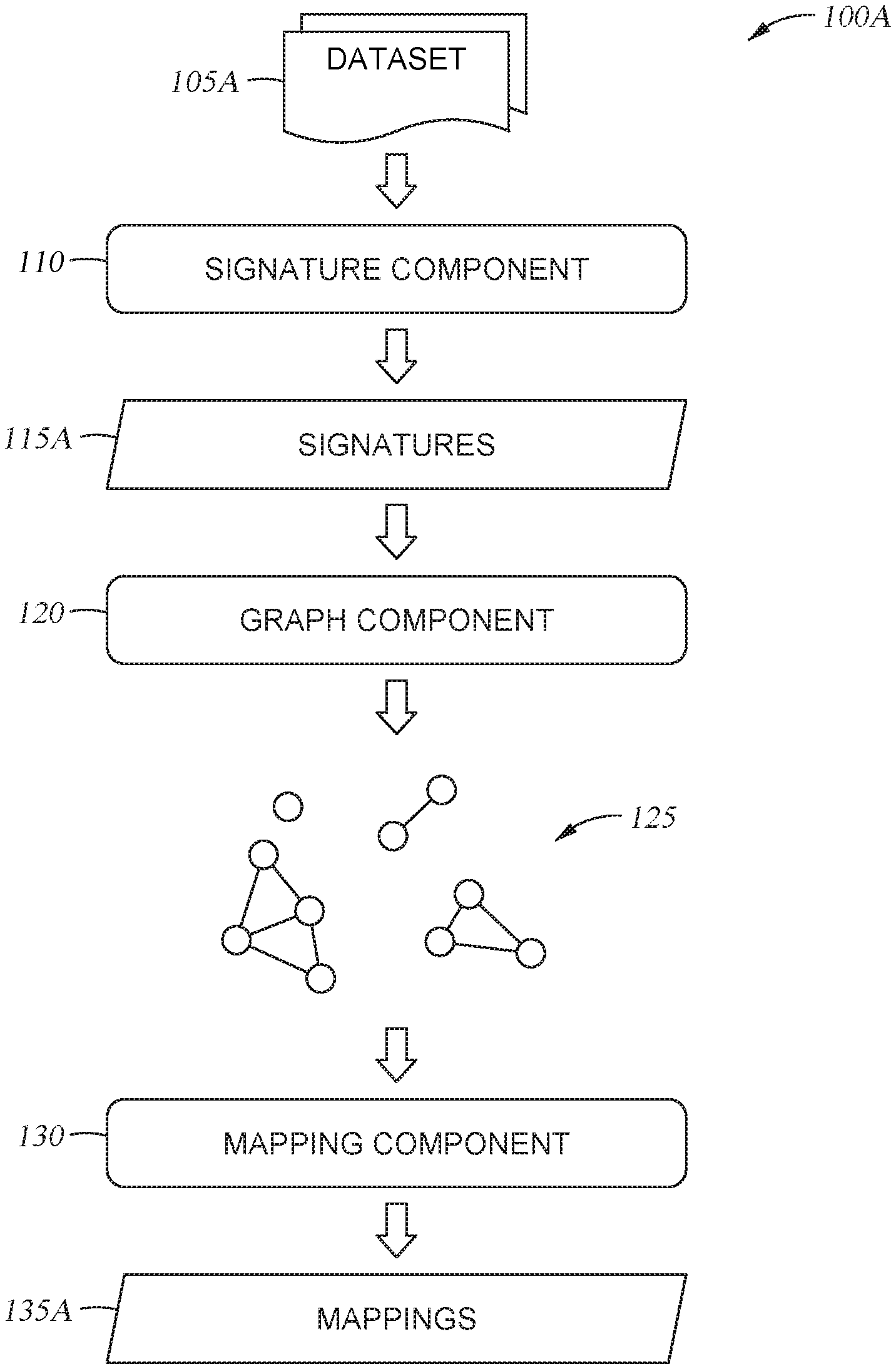
Workflow para la Normalización de Datos
| Paso | Descripción |
|---|---|
| Recepción de Datos | Se recibe un conjunto de datos que incluye múltiples variantes de palabras canónicas. |
| Generación de Firmas | Se generan múltiples firmas para las palabras utilizando técnicas de LSH, incorporando un elemento de aleatoriedad. |
| Construcción del Grafo | Se crea un grafo donde cada nodo representa una palabra y los bordes conectan nodos con firmas coincidentes. |
| Selección de Palabras Pivote | Para cada subgrafo, se selecciona una palabra pivote basada en la frecuencia de las palabras asociadas. |
| Normalización | Se limpian los datos originales reemplazando las variantes de palabras por sus correspondientes palabras pivote. |
Aplicaciones de la Normalización de Texto
La normalización de texto a través de LSH no solo mejora la calidad de los datos, sino que también permite a las organizaciones escalar sus procesos de análisis de datos. Esto es especialmente importante en situaciones donde los datos deben ser procesados en tiempo real, lo que requiere un sistema eficiente y rápido.
Desafíos y Futuras Direcciones
A pesar de sus ventajas, el uso de LSH presenta desafíos, como la posibilidad de colisiones de hash indeseadas que pueden afectar la calidad de la normalización. Sin embargo, los métodos de poda dentro del grafo ayudan a mitigar estos problemas al eliminar conexiones débiles. Las futuras investigaciones podrían centrarse en mejorar aún más la precisión de la normalización y en explorar nuevas aplicaciones de LSH en diferentes dominios de datos textuales.
En resumen, la técnica de hashing sensible a la localidad representa un avance significativo en la normalización y limpieza de registros de texto, aportando mejoras sustanciales en la eficiencia del procesamiento de datos y en la calidad de los resultados de análisis.
Fuente: US11244156B1 – Locality-Sensitive Hashing to Clean and Normalize Text Logs