




Amazon SageMaker HyperPod: Entrenamiento y Despliegue de Modelos de IA a Escala Trillonaria
Amazon SageMaker HyperPod ha revolucionado el campo del entrenamiento de modelos de IA al ofrecer soporte para los UltraServers P6e-GB200, que incorporan hasta 72 GPUs NVIDIA Blackwell en un único sistema. Esta infraestructura permite alcanzar un rendimiento sin precedentes con 360 petaflops de cálculo en punto flotante denso y 1.4 exaflops en punto flotante disperso. Este artículo examina las especificaciones técnicas de los UltraServers P6e-GB200, sus beneficios en rendimiento y los casos de uso más destacados.
Especificaciones Técnicas de los UltraServers P6e-GB200
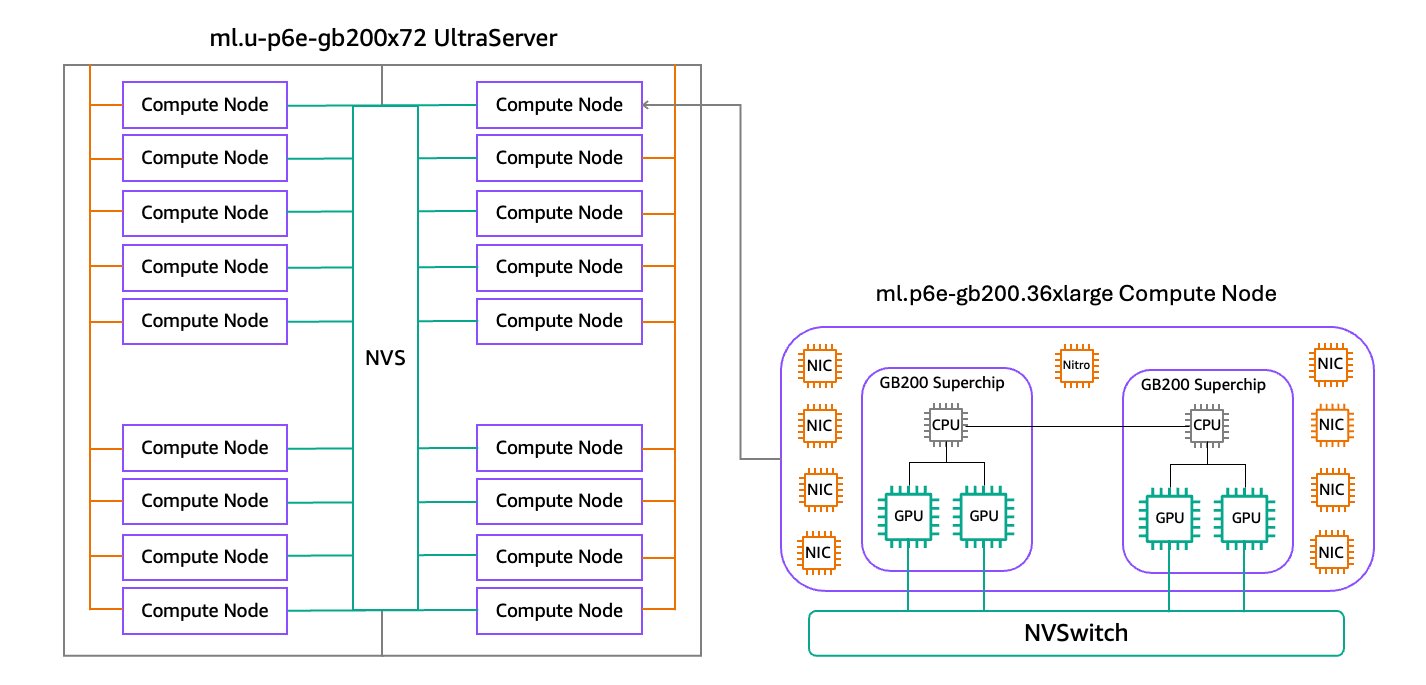
Los UltraServers P6e-GB200, impulsados por las GPUs NVIDIA GB200 NVL72, conectan 36 CPUs NVIDIA Grace y 72 GPUs Blackwell en un único dominio NVLink. Cada nodo de computación ml.p6e-gb200.36xlarge incluye dos Superchips NVIDIA GB200 Grace Blackwell, lo que mejora significativamente el rendimiento del modelo. La configuración de los UltraServers se presenta en dos tamaños:
- ml.u-p6e-gb200x36: incluye 9 nodos de computación, totalizando 36 GPUs Blackwell.
- ml.u-p6e-gb200x72: incluye 18 nodos de computación, totalizando 72 GPUs Blackwell.
Beneficios de Rendimiento de los UltraServers
Los UltraServers P6e-GB200 ofrecen múltiples ventajas que los posicionan como una opción ideal para el entrenamiento de modelos de IA, entre las que destacan:
Poder de Cómputo y GPU
Con un acceso de hasta 72 GPUs Blackwell en un único dominio NVLink, los UltraServers permiten un rendimiento excepcional en cálculos. Cada Superchip Grace Blackwell ofrece 10 petaflops de cómputo denso y 40 petaflops de cómputo disperso, además de hasta 372 GB de memoria HBM3e. Esta configuración mejora el ancho de banda entre GPU y CPU, resultando en una mayor eficiencia.
Redes de Alto Rendimiento
Los UltraServers proporcionan hasta 130 TBps de ancho de banda NVLink de baja latencia entre GPUs, mejorando significativamente la comunicación en cargas de trabajo de IA a gran escala. Con hasta 1.8 TBps de interconexión entre GPUs y soporte para hasta 17 tarjetas de interfaz de red físicas, el rendimiento de la red es optimizado para un funcionamiento fluido.
Almacenamiento y A través de Datos
El soporte de almacenamiento NVMe SSD de hasta 405 TB permite manejar grandes conjuntos de datos y realizar chequeos rápidos durante el entrenamiento. Además, se puede acceder a sistemas de archivos compartidos de alto rendimiento como Amazon FSx para Lustre.
Casos de Uso para UltraServers
Los UltraServers P6e-GB200 son ideales para entrenar modelos con más de un billón de parámetros gracias a su dominio NVLink unificado, memoria ultrarrápida y ancho de banda elevado entre nodos. Esta arquitectura permite una rápida iteración y mejora de modelos de IA, siendo especialmente adecuada para aplicaciones de inferencia en tiempo real.
Al combinar con NVIDIA Dynamo, los UltraServers logran un rendimiento notable, especialmente en modelos de lenguaje de contexto largo. Esto permite una gestión más eficiente de ventanas de contexto grandes y aplicaciones de alta concurrencia.
Planes de Entrenamiento Flexibles para UltraServer
La capacidad de los UltraServers P6e-GB200 está disponible a través de planes de entrenamiento flexibles en la Zona Local de AWS en Dallas. Esto permite a las organizaciones configurar y optimizar la infraestructura según sus necesidades específicas de entrenamiento y despliegue.
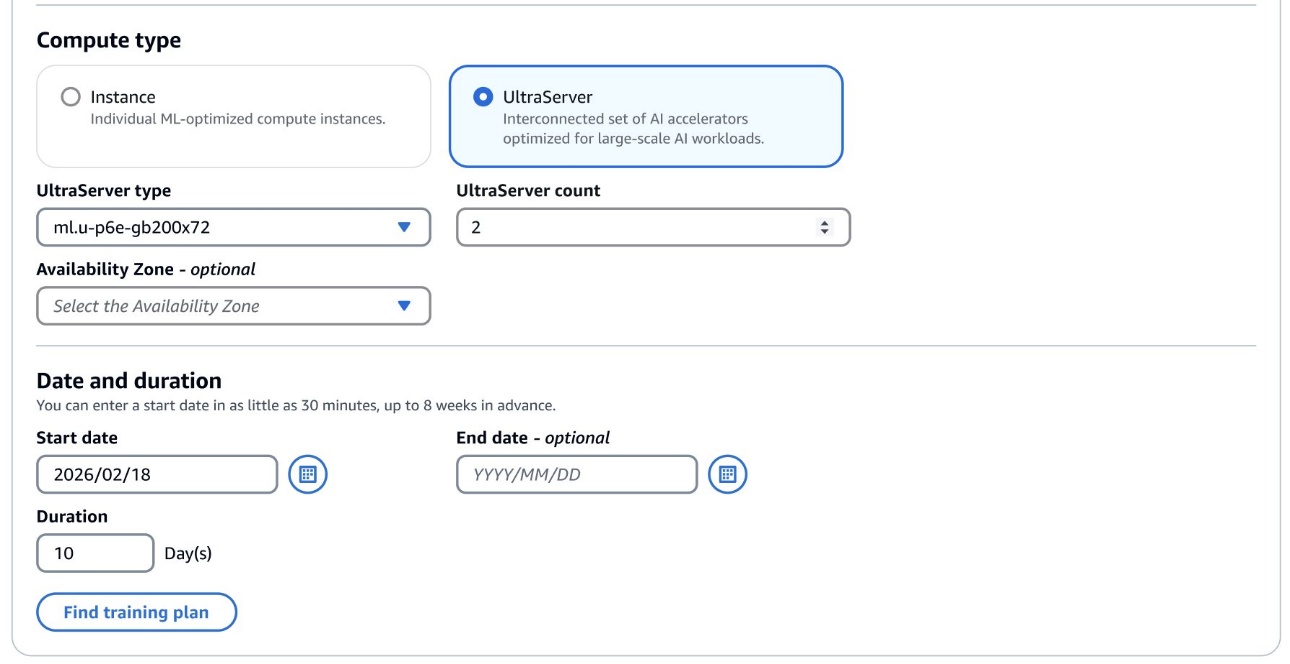
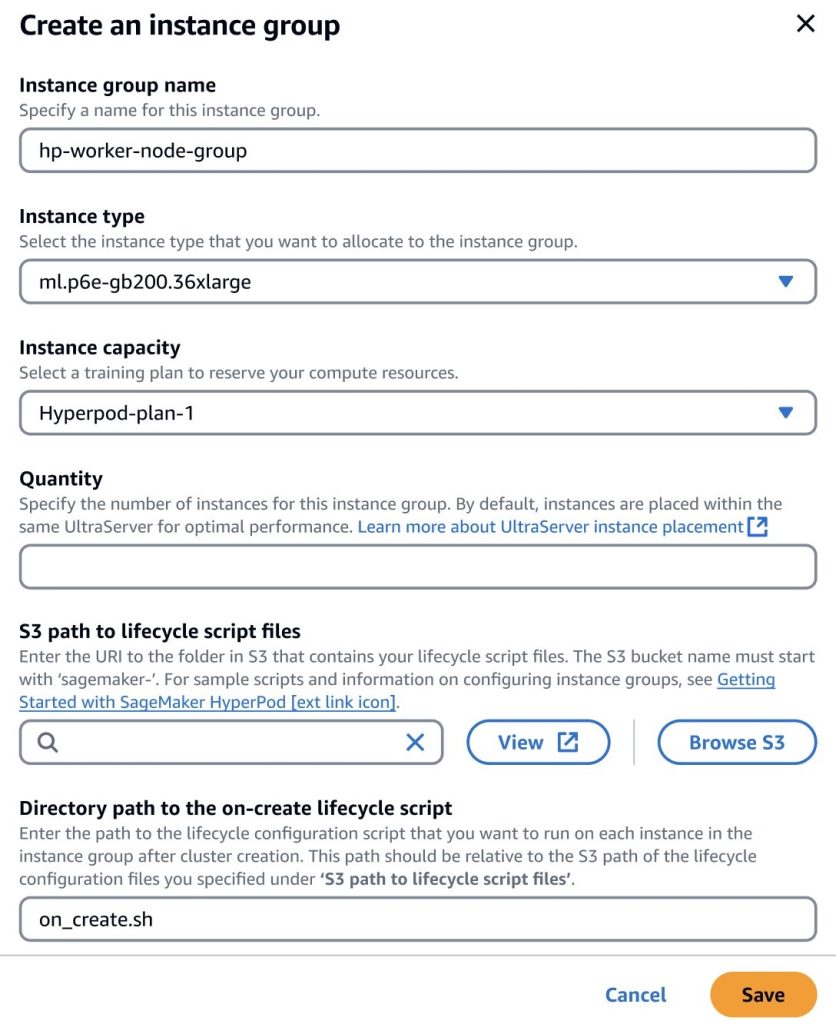
Creación de un Cluster UltraServer con SageMaker HyperPod
Después de adquirir un plan de entrenamiento para UltraServer, se puede añadir capacidad a un grupo de instancias dentro del clúster SageMaker HyperPod. La optimización automática de SageMaker garantiza que las GPUs estén interconectadas dentro del mismo dominio NVLink, mejorando el rendimiento de transferencia de datos para las tareas de entrenamiento.
Nota: Este contenido original ha sido modificado con IA y revisado por un especialista.



